The Inflation and Deflationary Trends in the Global Economy, or ‘the Japanese Disease’ is Spreading
скачать Авторы:
- Grinin, Leonid - подписаться на статьи автора
- Korotayev, Andrey - подписаться на статьи автора
Журнал: Journal of Globalization Studies. Volume 5, Number 2 / November 2014 - подписаться на статьи журнала
Recently among numerous concerns over the European and partly American economies the danger of deflation is rather frequently mentioned. The scholars cite the Japanese economy which has been suffering from deflation for the last two decades despite the large investments in economy and the government's efforts to increase inflation. Similarly, notwithstanding many trillions of dollars, euro, pounds and yen that were invested in economies over the past few years, the inflation in the Western countries still remains low.
On the whole, there are reasons to maintain that European countries suffer from ‘the Japanese disease’, and this disease can progress or even become chronic. The USA, although to a lesser extent, has the signs of the disease as well.
As a result, the financial infusions can become permanent, as it happened in Japan. The present paper defines the reasons of the problem, explains the irregularity of the inflation-deflation processes in the world and also gives some forecasts.
Keywords: inflation, deflation, quantitative easing, prices, investments, center, periphery, the Japanese economy, demand, economic laws.
The present-day world economy lacks a powerful and developed global mechanism of monetary and nonmonetary measures similar to the regulation at the national level and this has become one of the main causes of the current global financial crisis (see Grinin and Korotayev 2010b). Thus, at the supranational level there operate objective economic laws are opening; they manifest themselves, as before, in the successive short and long cycles of economic activity within national market economies. The cyclic regularity is manifested in the booms and recessions of the medium-term Juglar cycles (see, e.g., Juglar 1862, 1889 [1862]; Tugan-Baranovski 1894, 2008 [2013]; Schumpeter 1939; Grinin and Korotayev 2010a, 2012; Grinin, Malkov, and Korotayev 2010; Grinin, Korotayev, and Malkov 2010; Grinin, Korotayev, and Tsirel 2011), and also in the inflation and deflation phases of long Kondratieff cycles. Let us note that Nikolai D. Kondratieff was the first to make an attempt to present a systematic theory of such fluctuations of conjuncture (Kondratieff 1922/2002; 1925/1993; 1926, 1926/2002; 1928; 1928/2002; 1935, 1984, 1988[1923], 2002), but these fluctuations had been noticed much earlier (see, e.g., Tooke and Newmarch 1858–1859; Jevons 1884; Sauerbeck 1886; Wicksell 1898; Parvus 1901, 1908; Lescure 1912, 1932[1907]; Sombart 1911; Aftalion 1913; Van Gelderen 1913; Lenoir 1913; Mukoseyev 1914; Bresciani-Turroni 1917; Cassel 1918; Kautsky 1912, etc.).
The present-day world economy possesses some other features which allow attributing to it some phenomena which have already gone to the past as a result of government regulation. Some of them were mentioned in our works (see, e.g., Grinin 2012a, 2012b; Grinin, Korotayev, Malkov 2010, Grinin, Malkov, and Korotayev 2010; Grinin and Korotayev 2010a; 2012: Ch. 2). One can also note that since there is no common world-wide social legislation on labor, the laws of severe competition act with respect to most basic commodities when the low standard of living and high exploitation contribute to low commodity prices. As we shall see below, the cheap export coming from increasing number of countries with low standard of living contributes to a partial restraining of inflation rates in wealthy countries. But it often has no impact on raw materials. On the whole, there is a disproportion between the raw material production countries and countries that produce commodities.
The above-mentioned (and some other) analogies between world economy and national economies lacking government regulation can help to explain the cycles of world conjuncture and its inflation-deflation trends.
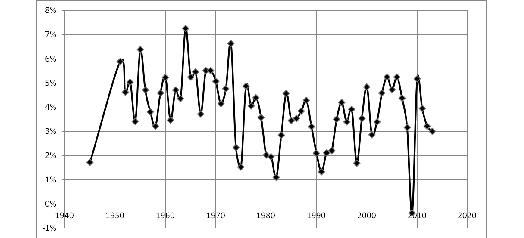
Recently, alongside with numerous problems in European (and partly American) economies, one quite often mentions the danger of deflation which would seem long-forgotten. In the nineteenth and the first half of the twentieth century, from time to time the deflation would put pressure on economies, nibbling away at entrepreneurs' profit. The deflation meant the decline in rate of return, bankruptcy and other critical events.1 The Great Depression was also connected with the Great Deflation and significant drop in prices (Fig. 1).
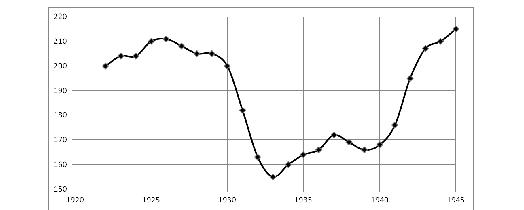
Source: David, Solar 1977: 16–17 (Table 1).
However, after the Second World War and especially, starting from the 1960s, the inflation became the main problem which persisted even in the 1970s when one observed a serious decline in Western economy due to the oil prices growth. During the economic downturn, prices usually fall or at least do not rise; meanwhile, at that period the prices grew at the background of economic decline, thus giving rise to a new dangerous phenomenon called ‘stagflation’. In short, the deflation was forgotten as something remote and as a historical archaism.2 There appeared theories of secular inflation, organically inherent in current economy based on paper money (not dependent on gold) and on central banks which make credits of their own will. In the 1980s, the fight against inflation required great efforts. Then the 1990s brought a hyperinflation in the former socialist countries and in a number of developing countries (Fig. 2). But later the hyperinflation would occur from time to time, for example, as it happened in Zimbabwe.
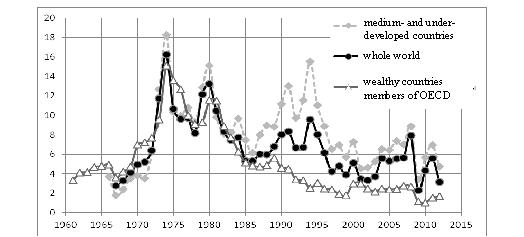
Source: World Bank 2014: NY.GDP.DEFL.KD.ZG.
Against this background, Japan was a strange and difficult to explain exception (see Fig. 3) as after the crisis of the 1990s (caused by the burst of the housing bubble) it began to suffer from deflation. The year of 1994 turned critical in this regard.
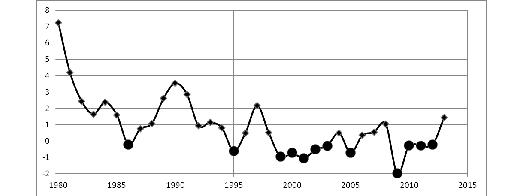
Note: The black circles denote the years with negative values (i.e., the deflation years).
Data source: IMF 2014. Calculated using consumer prices index.
After the Second World War, this was the first case when a developed economy suffered from the consumer deflation. It was considered an achievement when in some years they succeeded to raise inflation by means of massive credit expansion. The Japanese Prime Minister Shinzō Abe aims at reaching the inflation target of 2 per cent. At present (late 2014) due to efficient measures Japan has almost reached this level (e.g., in July, 2014 the prices grew by 0.7 per cent year on year, and in August 2014 compared to August 2013 the prices grew by 3.1 per cent). But how long will this trend persist? And most important, what will be the cost of this inflation?3The situation would seem absurd to the countries suffering from inflation but the measures taken by the Bank of Japan and the Japanese Government are really amazing in terms of their scale. The most surprising is that despite numerous programs of stimulating economy and astronomic sums of money spent for these purposes and for bank rescue and despite the fact that the Japan public debt is, perhaps, the highest among the developed countries, the economic growth in Japan has still remained rather weak for two decades. Sometimes it is followed by the decline in production (as it happens in 2014). In the period from 2003 to 2007, the general rise gave impetus to a moderate increase but later the crisis had nearly brought about the collapse of the Japanese export and industry. Thus, in Japan one can observe an ‘inverted’ stagflation. The economists generally fail to identify the causes of this prolonged ‘Japanese disease’ (see, e.g., Hilsenrath 2010). In 1998, to describe this situation Paul Krugman used the term ‘the liquidity trap’ which had been introduced by Keynes. This term describes a situation when monetary instruments including lending rates and currency emission do not work and do not stimulate the demand (Krugman 2013).4 Now he considers (not without reason) that other Western economies have also fallen into such a trap. But this does not explain much. The mechanism of such trap is not clear, Krugman's recommendations which the experts call ‘blowing bubbles’ (Nikolskiy 2013; Whitney 2013) seem dangerous.5 The bubbles tend to burst and are rather costly.
On the whole, the situation seems rather mysterious. There are many factors contributing to increasing debt, namely: credit rates decrease to the limit (zero), the Central Bank performs all kinds of open market operations (accumulates debt securities with the purpose of creating additional money liquidity), high costs for the state and low profit from the taxes, etc. There are other stimulating actions (in particular, reduction in taxes and tax increase, direct money distribution, changes in banking rules, etc.). But the long-expected inflation does not start. But at the same time, other indicators in Japan are quite good, for example, the high standard of living and life expectancy. And there is also significant scientific and technological progress.
One could attribute such a paradoxical situation (when there is a large amount of money in economy but inflation is still absent) to the ‘mysterious Japanese soul’. Sometimes they argue that the Japanese population is getting old and people do not want to spend money but prefer to save it (the Japanese have substantial savings); besides, contrary to the Europeans and Americans, the Japanese are not disposed to consumerism. It makes some sense (especially in the context of population ageing) but this is far from the only reason. The symptoms of the ‘Japanese disease’ have become apparent in Europe (see Fig. 4) and to some extent in the USA.
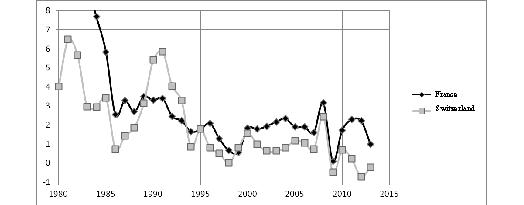
Data source: IMF 2014. Calculated using consumer prices index.
Therefore, the reasons lie in the common features of developed economies and in the global economy as a whole.
In fact, in recent years a huge amount of money has been invested in the Western economy. The interest rates have declined to the Japanese (zero) level.6 But that has not produced the desired effect: the growth is actually weak and a number of European countries even have a negative growth rate. At the same time, people are not willing to increase their consumption and number of credits, while the businessmen do not invest actively despite cheaper loans. The USA in addition to reduced rates until recently also implemented quantitative easing by buying every year government bonds and spending many hundreds of billions of dollars (and overall trillions, about 3 trillion over the past years) on ‘bad’ financial assets. However, even in the USA the efficiency of emissions and easings is not high. Europe also intends to use quantitative easing (which is strongly recommended).7 And in fact, the reduction of quantitative easing immediately caused problems with developing markets and currencies and later with American stock market (especially NASDAQ). In the summer and autumn of 2014, the reduction of quantitative easing (together with some other factors) made dollar gain against other currencies and to a certain extent contributed to decreasing oil prices. The world economy is distorted as it has huge disproportions. But the elimination of these disproportions is very painful so the quantitative easing turns rather helpful in this situation, it is like an injection for a drug addict.
But the strangest thing is that despite trillions of dollars, euros, pounds, yen, injected into economy in recent years, the inflation in Western economies remains low. And here one should keep in mind that most part of the invested money was created out of thin air through the policy conducted by the Central Bank. The USA failed to reach the inflation target of 2 per cent (which was assumed to be the indicator to stop the quantitative easing). In Europe the inflation is even lower and threatens to turn into deflation. In 2013, the average inflation rate in OECD countries was 1.5 per cent (in 2012 it was 2.2 per cent), which was below the official target rate of about 2 per cent (in the first months of 2014 the inflation rate was with some fluctuations almost the same as in 2013). The inflation rate decrease presents the greatest risk for the Eurozone. Thus, in October, 2013 the annual inflation of consumer prices amounted to 0.7 per cent (it is a slump if compare to 2.5 per cent in 2012). In 2013, the inflation in the Eurozone was the lowest since the introduction of the Single European Currency. In September 2013, in the USA the inflation amounted to 1.2 per cent (in July 2013 it was 2.2 per cent) while the basic rates which are determined by the Federal Reserve System, remain at 1.2 per cent (in 2014 the inflation slightly increased). The only large developed economy where the prices grew quite fast in 2013 was the British economy (inflation amounted to 2.7 per cent there) (Vestifinance 2013). But in 2014 the inflation decelerated in Great Britain as well. It remains below the Bank of England's 2 per cent target.
All this seems even stranger than at first sight. It is obvious that something has fundamentally changed both in the Western and in global economy. But the economists fail to define the essence of this change. Where does money go? Why does the currency emission fail to accelerate inflation? It is very difficult to comprehend the situation. Nevertheless, we would like to present our assumptions about the causes of this situation of ‘disappearance of inflation’.
First of all, economic laws still are in force but with certain modifications. These modifications are related to the development of the economic and financial globalization and also with the so called financial revolution which made the international capital circulation much faster and with more freedom (see, e.g. Doronin 2003; Mikhailov 2000; Rubtsov 2000; 2011; Grinin, Korotayev 2010a, 2010b). In any case in the conditions of currency emission ‘the disappearance of regular inflation’ means that without this emission either the deflationary bias is increasing or inflation gets transformed. Below we will consider both situations.
Inflation at Different Levels and in Different Respects
We should take into consideration the fact that inflation is an economic variable which is measured using particular methods. However, we observe the price increase not only within the market basket (especially in the US market basket which does not include food and energy). In this respect one can assume that statistics can be manipulated for political benefits. It is rather probable as regards the USA, especially in the period before crisis (see, e.g., Akaev, Korotayev, and Fomin 2012).
Let us suppose that the US statistics is misleading. But why should Japan make figures confirm the deflation? On the contrary, they could easily show that inflation is rising once it is so desirable. The same refers to Europe. Thus, the calculations methodology is of minor importance in this case.
Taking into account that inflation remains the major threat in developing countries, one can assume that today due to the peculiar methods of calculating, the Consumer Price Index can strongly depend on the consumption patterns. The more food products and essential commodities are included, the more evident becomes the consumer inflation.
Now let us consider several types or levels of inflation as the consumer prices constitute the lower level of inflation while the asset price inflation forms the second level. (Let us note that this tendency is not new. Before the Great Depression of 1929, the level of consumer prices remained the same while the level of asset prices was increasing very fast). In 2013, the US GDP rose by 1.9 per cent, the inflation was 1.1 per cent, and stock market increased by 35 per cent.
Thus, if the amount of circulating money increases more than the economic growth requires it and there is no inflation, it means that money goes to the sectors where inflation is not measured (as an inflation). However, in these sectors either the asset value grows or the prices maintain a stable level or increase, or the bubbles are blown, etc. These can be stock markets (shares and securities), raw material markets, real estate markets, etc. Meanwhile, the value of assets becomes an independent component which is not closely related to the actual situation at the enterprises.
Global and National Inflation
The expanding financial and economic globalization together with growing financial sector in general and financial services as a part of GDP (and with the absence of obstacles for a rapid capital transfer) has led to the situation when the emission of money in some places (centers) can cause inflation in other countries. However, the emission of money affects national economies, and this impact is in a way similar to the increase in gold production during the gold-standard period. Indeed, the rapid increase in gold production between the 1850s and 1860s in California and Australia pushed the prices up in many countries. However, contrary to nineteenth-century situation when prices grew fastest in the places of gold mines, today (taking into account that money flows can be immediately transferred for many thousand kilometers) the consumer inflation may not be perceived in the centers of emission (as the movement of air is hardly perceived at the epicenter of a typhoon).
Besides, one should take into account the international division of labor. On the one hand, the Western countries produce and supply capitals and world currency to all economies of the world (but if a certain part of it is created “out of thin air”, then there may occur a peculiar effect of the simultaneous export of inflation and deflation); on the other hand, the developing countries produce cheap consumer goods which are in growing numbers supplied to the developed countries. Increasing amounts of money from the core countries go to other countries and affect inflation there in different ways.8 This can be called an exported inflation. At the same time, the Western countries get cheap import from the developing countries and this also contributes to low inflation. But we should note that export of inflation is not always bad. On the contrary, in current situation it can significantly stimulate the economic growth (since the Keynesian times the moderate inflation is considered as a catalyst for the economic growth). However, the dependence on the fluctuations of economic flows makes the developing markets extremely vulnerable when any external change can cause deterioration.
As we have already noted, the major part of emission goes not to consumers' expenses but flows to assets and contributes to raw materials increasing price (although this often does not correlate with the economic situation).9 However, in the second half of 2014 the oil prices started to plunge, which can probably strengthen the deflationary trend. It is very important to realize that on the global scale it is just these capitals that support high oil and commodity prices which would drop otherwise. Thus, the emission spreads all over the world without visible manifestations, but this imposes inflation tax on all countries and stimulates the growth of resource economies (including Russia's) sustained via high prices. Thus, due to the pointed factors, the characteristics and manifestations of inflation change and gain a more global character. Inflation becomes a part of the international division of labor but under the conditions of labor division the benefits and problems are not equally distributed between the actors and countries and depend on the characteristics of a system. Consequently, with a certain level of average world inflation there may be deflation in some countries while the others will suffer from high inflation (thus, in addition to the internal factors the global ones can also produce a certain effect).10
The global capital flows have a great influence on the value of currency causing its devaluation and revaluation irrespective of internal factors and trade balance and these fluctuations also affect inflationary processes. The peculiarities of international monetary system make the countries with soft currencies transmit inflation to their own territory. Forced to accumulate foreign exchange reserves, they emit national currencies in connection with them and thus accelerate domestic inflation (in particular, Rothbard pointed this in his works [Rothbard 1977, 1994, 1995, 2002, 2005]).
Why does Capital Flow from the Western Countries?
If the return level is low, then capitals search for more profitable applications. As a result, the issued funds are invested not only in national economy but also in other national and world assets and become the source of capital exports and ‘fertilize’ the developing countries' growth.11 In 1990 when its economy started to fight with inflation, Japan had become the largest capital exporter and the largest loaner. The economic improvements in East Asia were supported by the Japanese (as well as American and European) funds for which their domestic capital markets had become tight. In addition to the corporations' own profits, the Japanese Central Bank's low interest credits together with the emission have obviously contributed to such powerful outflow of the Japanese capital (see Bonner and Wiggin 2003). In general, in the 1990s, ten economic development programs were launched totaling 100 trillion yen or about 900 billion dollars (Powell 2003: 111; Herberer 2003: 145; Bonner, Wiggin 2003). The same refers to other Western economies.
The export of capital under low interest rates is the export of deflation (and the exporting countries become the source of deflation) which in other (importing) countries can transform into the inflation (if the latter issue their own currency for imported foreign capital as, e.g., they do it in Russia, China etc.). The more intermediaries there are, the more vigorous can be the transformation. It is similar to the situation with food when products are purchased from the farmers at low prices but in the process of selling to the ultimate consumer the prices significantly increase.
In general, the growth of the financial sector is not accidental. In the absence of the golden anchor (i.e., gold standard) the necessity to save money from devaluation and increase capital (to give dividends to the owners of the capital) requires a huge amount of highly qualified specialists. The new technologies of rapid transfer and multiple insurance (hedge) of money impede the deflation of the assets and contribute to some leveling of the inflation in the world. However, recently we generally observe a more evident transfer of inflation from the developed to developing countries than in the opposite direction.
The World Deflationary Bias and Mechanisms
One can also explain the weak inflation in Western countries by the strong global deflationary processes and mechanisms which reduce inflation caused by huge emissions. If not for the emissions, the deflation would be more clearly manifested in Western economies. The experts of the international financial organizations realize this quite well and press to continue emission. What are the reasons to maintain that at present the deflationary trend prevails?
Firstly, we should note that at present we observe the downswing phase of the fifth Kondratieff wave (see Tables 1–2 and Figs 5–6). Kondratieff himself identified the following long waves and their phases (see Table 1).
Table 1
| Long wave number | Long wave phase | Dates of the beginning | Dates of the end |
| I | A: upswing | The end of the 1780s – beginning of the 1790s | 1810–1817 |
| B: downswing | 1810–1817 | 1844–1851 | |
| II | A: upswing | 1844–1851 | 1870–1875 |
| B: downswing | 1870–1875 | 1890–1896 | |
| III | A: upswing | 1890–1896 | 1914–1920 |
| B: downswing | 1914–1920 |
|
The subsequent students of Kondratieff cycles identified additionally the following long-waves in the post-World War I period (see Table 2).
Table 2
‘Post-Kondratieff’ long waves and their phases
| Long wave number | Long wave phase | Dates of the beginning | Dates of the end |
| Three | A: upswing | 1890–1896 | 1914–1928/2912 |
| B: downswing | 1914 to 1928/29 | 1939–1950 | |
| Four | A: upswing | 1939–1950 | 1968–1974 |
| B: downswing | 1968–1974 | 1984–1991 | |
| Five | A: upswing | 1984–1991 | 2005–2008? |
| B: downswing | 2005–2008? | ? |
Sources: Mandel 1980; Dickson 1983; van Duijn 1983: 155; Wallerstein 1984; Goldstein 1988: 67; Chase-Dunn, Podobnik 1995: 8; Modelski, Thompson 1996; Berend 2002: 308; Bobrovnikiv 2004: 47; Pantin, Lapkin 2006: 283–285, 315; Ayres 2006; Linstone 2006: Fig. 1; Tausch 2006a; 2006b: 101–104; Thompson 2000; 2007: Table 5; Jourdon 2008: 1040–1043. The last dating (2008) is suggested by the authors of the present paper (Grinin, Korotayev 2012; Grinin, Korotayev, Tsirel 2011; Korotayev, Tsirel 2010а; 2010b, 2010c; Korotayev, Khaltourina, and Bojevolnov 2010: 188–227). Closer dating are also suggested by some other scholars (see Lynch 2004: 230; Pantin, Lapkin 2006: 315; Akaev 2010; Akaev, Sadovnichiy 2010).
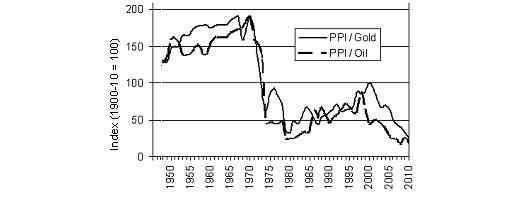
Source: Maddison 2010 (1940–2008); IMF 2014 (2009–2013).
Sources: BP 2010; Scheglov 2009; Grinin, Korotayev and Tsirel 2011: 77.
The deflationary and depressive tendencies increase on the downswing phases (see Grinin and Korotayev 2012, 2014; Grinin 2012a, 2013; Korotayev and Grinin 2012, 2014 for details about K-waves, their phases, and periodization). The deflationary factors persist even during the periods of recession and depression (they can only be mitigated). In the previous period between the 1990s and 2000s the additional emission of dollar and the deficit of balance of payment played the role of California's gold (in the period from 1850 to the 1860s) and increased the inflation in some places and sectors while blowing ‘bubbles’.
Secondly, inflation is multi-faceted. In particular, one should distinguish cost inflation and demand inflation. The cost inflation can have severe consequences especially under non-competitive conditions. The stagflation of the 1970s was connected with cost inflation but not with demand inflation. There was no alternative to oil then.13 However, globalization has undermined some opportunities for the cost inflation even in the services sector since the rapid means of communication made it possible to outsource the most expensive services. The demand inflation mainly depends on the growing demand. However, there is no such growth in the developed countries.
Thirdly, one should consider not only the emission of money but also the factors that level it, namely:
a) the fact that in the period of crisis many capitals were burned or frozen (“garbage assets”). As we noted, the crisis of 2008–2009 can be called the crisis of overproduction of money (Grinin 2009). The current emission partially substitutes money for these garbage assets. If additional money was not issued, prices would drop and the remaining ‘bubbles’ would completely blow out. In this case, the real deflation would start and restore the health of the world economy but at the same time it would inflict numerous losses (including for the raw commodity exporters).14 During the previous decades, there was a tremendous increase in monetary assets. Thus, over the twenty years (between 1980 and 1999) the world market capitalization increased by 13 times while the world's aggregate GDP increased only by 2.6 times. As a result, the ratio of capitalization to GDP increased from 23 per cent to 118 per cent. In the 2000s, the capitalization increased not that much, it only doubled, and its growth rates correlated with the GDP growth rates (see Sulakshin 2012: 226–227). However, the emission of derivatives was increasing rapidly, and in 2007 and 2008 it exceeded 2.2 trillion dollars per year: yet, due to the tightening of legislation and some other factors the volume of their emission is reduced.
b) The necessity to support global trade. While in the nineteenth century gold played the role of world money, at present dollars and partly other currencies perform this function. Therefore, some amount of money should be additionally invested into the world economy annually. Let us recall that in recent decades the world trade growth rates surpassed the growth rates of the world economy (see Fig. 7); and thus, a larger amount of world money has been needed.
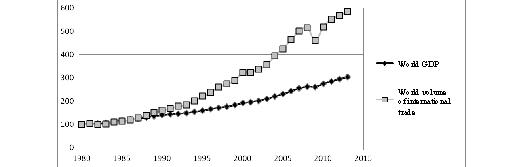
Source: IMF 2014.
Against this background, the USA, Japan and some other countries get benefits and this is a situation similar to the nineteenth century when the USA and Australia got extra bonuses from growth in gold mining. The world economy growth even by 2 per cent per year means an increasing demand for dollars, hundreds billions of dollars which are invested through the emission.
c) Hoarding means accumulation and removal from circulation. On the global scale it took the form of accumulation of foreign exchange reserves which reached tremendous volumes and this contributes to the absorption of spare money. Over the last decade a number of countries have accrued their international reserves. That is the reason why the inflation is so low in the countries-issuers, but it is high in other countries (as we have already noted, the accumulation of foreign currency reserves is used by such countries to support the issue of their own currency). Besides, these countries accumulate a certain part of the reserves and different national funds in US and other countries' government bonds. Hoarding is expressed in private savings (up to hundred billions of dollars in cash are annually spent on these purposes).
d) The competition for goods and services export to the developed countries (for example, tourism can become cheaper due to new markets with cheap services and undervalued currency).
e) From time to time the circulation of money slows down, so the amount of money compensates for decelerating velocity of its circulation (according to Fisher equation). Taking into account the current slowdown of the world trade (and of the world financial services) and corresponding deceleration of the currency in circulation, the investment of extra capitals into international finance does not produce a congruent effect on inflation and even fails to keep the prices from decreasing.15 But in general the deceleration of the world trade has a negative impact on economic growth rates.
Deflationary and Depressive Factors Specific to the Western World
All other things being equal, the weak economic growth is mainly explained by the fact that the main reserves of growth were exhausted in respective societies. The evident reserve, which appeared to be mostly depleted in Japan in the 1990s, was demography. In the 1990s, the process of decline of economically active population began (see, e.g., Vimont 2000) which continues until now (see Fig. 8), but at present we also observe a natural decline in the population.
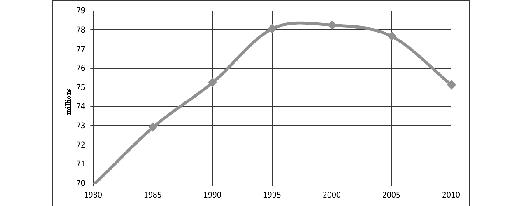
Source: UN Population Division 2014.
Thus, one of the main problem is the population ageing, its slow growth, or even depopulation in developed economies and this contributes to the weakening of the natural foundation for the economic growth. In the case of population decline, the percentage of working age population also decreases and thus, the economic growth gains different character and requires extra efforts (at present Russia has encountered a similar situation which resulted in a sharp decline of growth rates). In the situation of population ageing, when old people mainly have no problems with purchasing accommodation and durable goods (the problems of basic needs have already been solved) and think that they should save money for bad times, the stimuli for the economic growth change. The example of Japan demonstrates that in this case a country can exist even without economic growth just by transforming the economic structure. So there arises a new situation when there is no stagnation, but there is no growth either. This is a whole new situation. We do not know how long it will last. Of course, to a great extent it is, probably, artificially created, as the GDP growth rate is not an absolute indicator of an actual growth. Anyway, the situation remains alarming.
The next cause of ‘the Japanese disease’ is a very high standard of living which can hardly be adapted to decreasing growth rates. In Europe, for example, the number of working hours per worker is much smaller than in the USA and Japan. The drive to high standards of living, obviously, prevents investment and savings growth. In the USA there are much fewer social guarantees than in Europe and this has a positive effect on the economic activity, but they also tend to increase there. In general, population ageing together with social guarantees available for the electorate makes a tough problem of budget deficit and government debt due to low growth rates. And this is another reason why ‘the Japanese disease’ can exacerbate in Europe.
The third reason is that these countries are transforming into rentiers due to their specialization within the World System on the export of capital and receiving dividends and also due to their strong financial centers and financial sector. All this reminds the situation in Great Britain in the late nineteenth – early twentieth centuries when capital export and savings were source of subsistence for many people for whom deflation was profitable. At the same time the pound was stable. And now the United States live as a rentier largely due to the exceptional position of dollar in the international monetary system. High incomes from the foreign assets do not contribute to the growth of domestic economic activity and GDP.
The fourth reason is that the main reserve of the economic growth in Europe, the USA and Japan is the technological growth. However, in the situation of active export of capital and continued industry export (although there is evidence of the homewards stream) this factor is limited in its action at least until the development of new breakthrough technologies. The insufficient investments give no growth in demand.16 In Europe this is primarily connected with a hard economic situation and budget cuts; this is similar in Japan, with its ageing population which is less apt to innovations and more concentrated on saving money for bad times. The signs of ‘the Japanese disease’ begin to show up. In the USA, there is also an obvious tendency to repay debts and decrease the number of credits. Energy cost reduction, increase of taxes and insurance payments, deficit and trade balance reduction are used as supplementary anti-inflationary measures in the USA. Low interest rates on deposits also cause low inflation (and the outflow of capital). The most important sign (not only in the USA but also in Europe) is low credit rates which reduce cost inflation (on the contrary, in Russia and China the high credit rates increase cost inflation).
The fifth reason is the deindustrialization in developed economies in which the financial services and flows account for a larger share. And the service economy significantly differs from the previously existed type, similarly, as the industrial economy differed from the industrializing one. For example, while the crisis in 1970–1980 was associated with oil prices growth, the current crisis arises from the sharp decline in oil prices and it can make many businesses bankrupt. At present housing bubbles and other bubbles pose major threats because the emissions flow primarily into these financial structures. To some extent this is similar to pre-industrial and early industrial economy where basic capitals were separated from the economy (finance would concentrate mainly in serving public dept and large-scale trade). Bursting bubbles is unprofitable because it leads to bankruptcy and requires new niches for saving and growth of capital.
The sixth reason is the erosion of the middle class and growing inequality. Especially it is typical of the USA with its weak development of social system, because extra revenues from monetary emission means increasing or sustaining incomes of narrow class of people which leads to growing social stratification in developed countries.17 This can increase the risk of social unrest. But we also observe a growing social stratification in other developed countries. This tendency is typical of the largest Western states. Thus, the erosion of middle class provokes deflationary processes as the household incomes decrease (or stop growing), while in developing countries, on the contrary, the growing middle class affects the inflation rates.
Conclusion
On the whole, there are reasons to maintain that European countries suffer from ‘the Japanese disease’, and this disease can progress or become chronic. The USA, although to a lesser extent, also has the signs of the disease. As a result, financial injections can become constant, as this has already happened in Japan.
The main problem is that the driving force of the growth weakens and the economies cannot grow without emissions and financial injections. The worst is that they cannot grow even with financial injections; at best they can demonstrate a sluggish development. As a result the real business forces move to the spheres of financial and other technologies and this leads to decreasing investments into real technologies. In the situation of economic difficulties everyone requires emission on a growing scale. So there starts a certain emission race among states. However, in the situation of relatively low demand the emission will hardly bring a rapid increase of inflation, dollar devaluation, or other results. But, of course, it will leave its mark. However, we will most likely see the consequences in a few years and as usual they will come unexpectedly. The continuous accumulation of money and financial instruments (especially combined with their accelerated circulation or weakening of deflationary processes) can become a detonator. This situation will lead to the bursting of another financial bubble that can cause another large-scale crisis because the debt and emission overhang will significantly increase by that time. Besides, the central banks' manipulations cause remittance of money flows to the speculative channel (due to the actual repayment of debts by means of emission and repurchase of ‘bad’ assets) which significantly distorts the proportions and creates a large overhang in the form of overvalued exchange assets which are most likely to burst. Of course, it is very difficult to forecast the time, place and the trigger of that burst. One should take into account that many social funds and capital owners invest in stocks and this fact will make the collapse hard for everyone.
Thus, probably, the cycle of monetary over-accumulation within the World System has not finished yet and it will take several years before the abscess breaks somewhere. The situation can be exacerbated if more countries and their central banks (including ECB) are involved in the process of quantitative easing and the USA and Japan fail to cope with this process in the way they intend.
In the next few years the deflationary factors will prevail or even increase. According to Paul Krugman (in Hilsenrath 2010), it is time to focus on the stable trend of decrease and on its consequences. After all, everything indicates that we will have to deal with repressed economy for a long time. Remarkable efforts and reforms will be needed to overcome the economic depression. The time will show if Western countries are ready to such sacrifices.
* This research has been supported by the Russian Science Foundation (Project No 14-11-00634).
1 The complaints about the deflation were rather widespread, for example, at the times of ‘the Long Depression’ in the USA from 1873 to 1879 (which had been also called the Great Depression before the crisis of the 1930s). It was the longest recession in the history of the US economy, so it was even longer (though much less severe) than the Great Depression (see, e.g., Fels 1949: 69). It lasted for 65 months. And the whole period from 1873 to 1897 was also called the Long-wave Depression in the US economy. The same refers to Britain of the same period, but the situation there was much more difficult in some respects. Thus, Tugan-Baranovsky (2008 [1913]: 195) states that the stagnation in British trade had hardly ever been so continuous and destructive for the country as it was in the 1880s. ‘The complaints about low prices, reducing all business profit, in the mid-1880s were common’ (Ibid.). At the same time it follows from the reports that ‘in some industries the production by no means had reduced, but there were complaints of no profit’ (Ibid.). Lescure was among the first who quite clearly identified the long depression and deflation between 1873 and 1893 (Lescure 1932[1907]: 167–168).
2 Moreover, Milton Friedman and other economists of this approach even stated that one could have easily escaped from the Great Depression if they had actively used quantitative easing. In our opinion, it is generally an illusion. The essence of the Great Depression was not only financial but this was a decisive, structural crisis which could not be easily resolved.
3 The sales tax was raised from 5 to 8 per cent. This resulted in a significant decline in demand and GDP in the second quarter of 2014 after its increase in the first quarter. At the same time this decline in the second quarter was the largest since 2009 reaching 7 per cent at an annual rate. There is still a hope that this decline is a temporary phenomenon; however, many would remember the year of 1997 when this tax was raised from 3 to 5 per cent and the economy fell into a twenty-month' recession. However, in the third quarter of 2014 the recession still continued.
4 Keynes explained this paradox by the fact that consumers delay their purchases hoping for price cutting. But the situation in Japan and in the West is much more complicated than this psychological obstacle to expansion of demand.
5 ‘All this confirms an important conclusion that as I said very early in the crisis, virtue becomes vice and prudence is folly. In our world, a responsible behavior is a way to economic failure’ (cited in Whitney 2013). Krugman proposes to keep the negative interest rates, to rise spending by any means and not to be afraid of increasing public debt. He recommends the politicians from the USA, Great Britain and other countries with independent currencies to be wiser and not to be afraid of default (Finmarket 2013).
6 Moreover, the European Central Bank has recently realized something that used to be just a theoretical possibility, namely, imposed a minus 0.1 percent interest rate on deposits. In other words, to encourage the credit expansion, the European Central Bank makes the banks pay the ECB to hold their money there. Now the banks should impose the negative interest rates on their clients. It means that they will not give money for keeping deposits but will get interests stimulating the growth of demand. And in this case the financial mirror-world will come true.
7 As stated in the International Monetary Fund report ‘Recovery strengthens, remains uneven’ (IMF 2014), the extremely low growth rates of consumer prices in developed countries, especially in the Eurozone, pose a threat to the global economic recovery.
8 At the same time the Central Bank's low interest rates make almost every financial operation profitable and that is the reason of tendency to conservatism (to invest into government bonds or some shares) which leads to deflation. Thus, the low interest rates contrary to the expectations can create a deflationary spiral.
9 Money does not fall directly into people’s hands (in the USA the taxes rose and the tax collection was tightened) but goes directly to the banks and financial companies. If 85 billion dollars were monthly given in the form of aid, the acceleration of inflation would be inevitable.
10 The development of globalization and emergence of new cheap manufacturers can produce an effect similar to the decline in crop and food prices in the nineteenth century (in the 1870s and 1890s). Just as the export of Russian and American cheap wheat in the 1870s and 1880s gave the European workers cheaper food but at the same time put pressure on the economy, today the consumers benefit from the Chinese and other export which puts pressure on economy.
11 The low-interest credits quite often obtained in the countries with artificially low rates are used for the purpose of buying more profitable assets in other countries.
12 The most noticeable variation in dates is observed at the threshold of the A and B phases of the 3rd Kondratieff Wave.
13 The inflation in Russia is in many ways related just to cost inflation due to natural monopolies.
14 The decrease in prices, for example, for aluminum, has led to the shutdown of some factories in Russia and some other countries. A more significant decrease could lead to the world (and national) GDP decline. That used to be the pattern of Juglar cycles. Now we do not observe the decrease but at the same time the growth is lacking either. The money injections act in a non-cyclical manner and are not the engine of the growth.
15 A sharp slowdown in global world trade dynamics in 2012 became one of the reasons of the weak economic growth in developed countries. The world GDP growth in 2012 by 2.1 per cent was accompanied with the growth of the world trade in real terms amounted 2.1 per cent in export and 1.9 per cent in import (compared with 5.2 and 5.1 per cent respectively in 2011). In nominal terms in 2012 the volume of world trade increased only by 0.2 per cent and amounted 18.2 trillion dollars. To a considerable extent this was due to the sharp decline in the world prices of a number of traditional export commodities such as coffee (–22 per cent), cotton (–42 per cent), coal (–21 per cent), iron ore (–23 per cent). However, the energy prices did not change much (+1 per cent) (Biryukova, Pakhomov 2013).
16 In 2012, global FDI declined by 18 per cent and amounted US$ 1.35 trillion. UNCTAD forecasted that in 2013 FDI will remain close to the 2012 level, with an upper limit of US$1.45 trillion. The recovery will be more prolonged than it has been expected mainly due to the global economic instability and political uncertainty. With the account of revival of investors' mid-term assurance, it is expected that the FDI flows can reach the amount of US$ 1.6 trillion in 2014 and US$ 1.8 trillion in 2015. There are still considerable risks associated with this growth scenario. The FDI outflows from the developed countries dropped to the level close to the level of 2009. The uncertain economic prospects make the developed countries' TNCs to maintain their wait-and-see approach with respect to new investments or to divest foreign assets, rather than undertake major international expansion. In 2012, 22 of the 38 developed countries experienced a decline in FDI outflow which constituted 23 per cent of the general decline (UNCTAD 2013). FDI flows to developed economies sharply declined. FDI inflows to developed economies declined by 32 per cent and amounted 561 billion dollars, this level was lastly achieved almost 10 years ago. There was a significant decline in FDI inflows in most developed countries, in particular, in the European Union which accounts for two thirds of the global FDI reduction. According to UNCTAD report, despite the struggle against tax havens their number increases which reduces expenses on business; the number of countries offering favorable tax conditions for SPEs (special-purpose entities) is also increasing.
17 In developing countries, on the contrary, the smaller role of financial sector leads to the growth in incomes of most people, so there is a growth of the middle class promoted by real economic growth and growing significance of the intellectuals.
Aftalion, A. 1913. Les crises périodiques de surproduction. T. 1 et 2. Paris: Rivière.
Akaev, A. A. 2010. Current Financial-Economic Crisis in the Light of the Theory of Innovation and Technological Economic Development and Management of Innovation Process. In Khaltourina, D. A., Korotayev, A. V. (eds.), The System-Based Monitoring: Global and Regional Development (pp. 230–258). Moscow: LIBROKOM. In Russian (Акаев А. А. Современный финансово-экономический кризис в свете теории инновационно-технологического развития экономики и управления инновационным процессом. Системный мониторинг: Глобальное и региональное развитие / Ред. Д. А. Халтурина, А. В. Коротаев, с. 230–258. М.: Либроком/ URSS).
Akaev, A., Korotayev, A., and Fomin, A. 2012. Global Inflation Dynamics: Regularities & Forecasts. Structure & Dynamics 5(3): 3–18.
Akaev, A. A., and Sadovnichiy V. A. 2010. On the New Methodology of the Long-Term Cyclical Forecast of the Dynamics of the World System and Russia. In Akaev, A. A., Korotayev, A. V., and Malinetsky, G. G. (eds.), Forecast and Modeling of Crises and World Dynamics (pp. 5–69). Moscow: LKI. In Russian (Акаев А. А., Садовничий В. А. О новой методологии долгосрочного циклического прогнозирования динамики развития мировой системы и России. Прогноз и моделирование кризисов и мировой динамики / Ред. А. А. Акаев, А. В. Коротаев, Г. Г. Малинецкий, с. 5–69. М.: ЛКИ/URSS).
Ayres, R. U. 2006. Did the Fifth K-Wave Begin in 1990–92? Has it been Aborted by Globalization? In Devezas, T. C. (ed.), Kondratieff Waves, Warfare and World Security (рр. 57–71). Amsterdam: IOS Press.
Berend, I. T. 2002. Economic Fluctuation Revisited. European Review 10(3): 305–316.
Biryukova, O., and Pakhomov, A. 2013. The Global Trade: Situation and Prospects. URL: http://ecpol.ru/2012-04-05-13-42-46/2012-04-05-13-43-05/788-mirovayatorgovlya-sostoy anie-i-perspektivy.html In Russian (Бирюкова О., Пахомов А. Мировая торговля: состояние и перспективы.).
Bobrovnikov, A. V. 2004. The Macrocycles in Latin-American Economies. Moscow: Institute of Latin America Studies RAS. In Russian (Бобровников, А. В. Макроциклы в экономике стран Латинской Америки. М.: Ин-т Латинской Америки РАН).
Bonner, W., and Wiggin, A. 2003. Financial Reckoning Day: Surviving the Soft Depression of the 21st Century. Hoboken, NJ: John Wiley and Sons.
BP. 2010. BP Statistical Review of World Energy 2010. URL: http://bp.com/statisticalreview.
Bresciani-Turroni, C. 1917. Movimenti di longa durata dello sconto e del prezzi. Giornale degli economisti e rivista di statistica 5(1).
Cassel, G. 1918. Theoretische Sozialökonomie. Leipzig: A. Deichert.
Chase-Dunn, Ch., and Podobnik, B. 1995. The Next World War: World-System Cycles and Trends. Journal of World-Systems Research 1(6): 1–47.
David, P. A., Solar, P. 1977. A Bicentenary Contribution to the History of the Cost of Living in America. Research in Economic History 2: 1–80.
Dickson, D. 1983. Technology and Cycles of Boom and Bust. Science 219(4587): 933–936.
Doronin, I. G. 2003. The Global Stock Markets. In Korolyov, I. S. (ed.), The World Economy: Global Trends for a Century (pp. 10–133). Moscow: Ekonomist. In Russian (Доронин И. Г. Мировые фондовые рынки. Мировая экономика: глобальные тенденции за 100 лет / под ред. И. С. Королева: М.: Экономистъ. С. 101–133).
Duijn, J. J. van. 1983. The Long Wave in Economic Life. Boston, MA: Allen and Unwin.
Fels, R. 1949. The Long-Wave Depression, 1873–97. The Review of Economics and Statistics (The MIT Press) 31(1): 69–73.
Finmarket. 2013. Krugman: The Developed Countries cannot Go Bankrupt. Finmarket, October 30.URL: http://www.finmarket.ru/main/article/3535583. In Russian (Кругман: Развитые страны не могут обанкротиться. Финмаркет, 30 октября).
Goldstein, J. 1988. Long Cycles: Prosperity and War in the Modern Age. New Haven, CT: Yale University Press.
Grinin, L. E. 2009. Global Crisis as the Crisis of Overproduction of Money. Filisofiya i obschestvo 1: 5–32. In Russian (Гринин Л. Е. Глобальный кризис как кризис перепроизводства денег. Философия и общество 1: 5–32).
Grinin, L. E. 2012a. Kondratieff Waves, Technological Principles, and the Theory of Production Revolutions. In Akaev, A.A, Grinberg, R. S., Grinin, L. E., and Korotayev, A. V. (eds.), Kondratieff Waves: Aspects and Prospects (pp. 222–262). Volgograd: Uchitel. In Russian (Гринин Л. Е. Кондратьевские волны, технологические уклады и теория производственных революций // Кондратьевские волны: аспекты и перспективы / отв. ред. А. А. Акаев, Р. С. Гринберг, Л. Е. Гринин, А. В. Коротаев, С. Ю. Малков, с. 222–262. Волгоград: Учитель).
Grinin, L. E. 2012b. Macrohistory and Globalization. Volgograd: Uchitel Publishing House.
Grinin, L. E. 2013. The Dynamics of Kondratieff Waves in the Light of the Theory of Production Revolutions. In Grinin, L. E., Korotayev, A. V., and Malkov, S. Yu. (eds.), Kondratieff Waves: The Range of Approaches (pp. 31–83). Volgograd: Uchitel. In Russian (Гринин Л. Е. Динамика кондратьевских волн в свете теории производ-ственных революций // Кондратьевские волны: палитра взглядов / отв. ред. Л. Е. Гринин, А. В. Коротаев, С. Ю. Малков, с. 31–83. Волгоград: Учитель).
Grinin, L. E., and Korotayev, A. V. 2010a. Global Crisis in Retrospective. Short History of Rises and Crises from Lycurgus to Alan Greenspan. Мoscow: KD LIBROKOM. In Russian (Гринин Л. Е., Коротаев А. В. Глобальный кризис в ретроспективе. Краткая история подъемов и кризисов: от Ликурга до Алана Гринспена. М.: ЛКИ/ URSS).
Grinin, L. E., and Korotayev, A. V. 2010b. Will the Global Crisis Lead to Global Transformations. 1. The Global Financial System: Pros and Cons. Journal of Globalization Studies 1(1): 70–89.
Grinin, L. E., and Korotayev, A. V. 2012. Cycles, Crises and Traps of the Modern World-System. Research of Kondratieff, Juglar and Secular Cycles, Global Crises, Malthusian and Post-Malthusian Traps. Moscow: LKI. In Russian (Гринин Л. Е., Коротаев А. В. Циклы, кризисы, ловушки современной Мир-Системы. Исследование кондратьевских, жюгляровских и вековых циклов, глобальных кризисов, мальтузианских и постмальтузианских ловушек. М.: ЛКИ/URSS).
Grinin L. E., and Korotayev, A. V. 2014. The Interaction between Kondratieff Waves and Juglar Cycles. In Grinin L. E., and Korotayev A. V. (eds.), Kondratieff Waves. Volgograd: Uchitel. In press.
Grinin, L. E., Malkov, S. Yu., and Korotayev, A. V. 2010. Mathematical Model of a Medium-Term Economic Cycle. In Akaev, A. A., Korotayev, A. V., and Malinetsky, G. G. (eds.), Forecast and Modeling of Crises and World Dynamics (pp. 287–299). Moscow: LKI. In Russian (Гринин Л. Е., Малков С. Ю., Коротаев А. В. Математическая модель среднесрочного экономического цикла // Прогноз и моделирование кризисов и мировой динамики / под ред. А. А. Акаева, А. В. Коротаева, Г. Г. Малинецкого, c. 286–299. М.: ЛКИ/URSS).
Grinin, L., Korotayev, A., and Malkov, S. 2010. A Mathematical Model of Juglar Cycles and the Current Global Crisis. In Grinin, L., Herrmann, P., Korotayev, A., and Tausch, A. (eds.), History & Mathematics. Processes and Models of Global Dynamics (рр. 138–187). Volgograd: Uchitel.
Grinin, L. E., Korotayev, A. V., and Tsirel, S. V. 2011. Developmental Cycles of Modern World-System. Мoscow: LIBROCOM. In Russian (Гринин Л. Е., Коротаев А. В., Цирель С. В. 2011. Циклы развития современной Мир-Системы. М.: Либроком/URSS).
Herberer, G. 2003. Good bye to the Japanese Miracle. In Kuryaev A. V. (ed.), The Master of Boom. Lessons from Japan (pp. 138–154). Cheliabinsk: Sotsium. In Russian (Херберер Дж. Прощай, японское “чудо”. Маэстро бума. Уроки Японии / под ред. А. В. Куряева, Челябинск: Социум, 2003. С. 138–154).
Hilsenrath, J. 2010. Deflation Defies Expectations – and Solutions. The Wall Street Journal. URL: http://online.wsj.com/news/articles/SB10001424052748704249004575384944103 200032?mg=reno64-wsj&url=http%3A%2F%2Fonline.wsj.com%2Farticle%2FSB1000 1424052748704249004575384944103200032.html.
IMF – International Monetary Fund. 2014. World Economic Outlook (WEO). Recovery Strengthens, Remains Uneven. Washington, DC: International Monetary Fund. Statistical Supplement. 2014. URL: http://www.imf.org/external/pubs/ft/weo/2014/01/weodata/ index.aspx.
Jevons, W. S. 1884. Investigations in the Currency and Finances. London: Macmillan.
Jourdon, Ph. 2008. La monnaie unique europeenne et son lien au developpement economique et social coordonne: une analyse cliometrique. Thèse. Montpellier: Universite Montpellier I.
Juglar, C. 1862. Des crises commerciales et de leur retour périodique en France, en Angleterre et aux États-Unis. Paris: Guillaumin.
Juglar, C. 1889 [1862]. Des crises commerciales et de leur retour périodique en France, en Angleterre et aux Etats-Unis. 2nd ed. Paris: Librairie Guillaumin et Cie.
Kautsky, K. 1912. Gold, Papier und Ware. Die Neue Zeit 30/1, Nr. 24 and Nr. 25: 837–847 and 886–893.
Kondratieff, N. D. 1922/2002. The World Economy and its Conjunctures During and After the War. In Kondratieff 2002: 40–341. In Russian (Кондратьев Н. Д. Мировое хозяйство и его конъюнктура во время и после войны. В: Кондратьев 2002: 40–341).
Kondratieff, N. D. 1925/1993. The Long Waves in Economic Life. In Kondratieff, N. D., Selected Works (pp. 24–83). Moscow: Ekonomika. In Russian (Кондратьев Н. Д. Большие циклы конъюнктуры. В: Кондратьев Н. Д. Избранные сочинения, с. 24–83. М.: Экономика).
Kondratieff, N. D. 1926. Die langen Wellen der Konjunktur. Archiv für Sozialwissenschaft und Sozialpolitik 56(3): 573–609.
Kondratieff, N. D. 1926/2002. The Long Waves in Economic Life. In Kondratieff 2002: 34–400. In Russian (Кондратьев Н. Д. Большие циклы экономической конъюнктуры. В: Кондратьев 2002: 341–400).
Kondratieff, N. D. 1928. Long Cycles of Economic Activity: Reports and Debates on them in the Institute of Economic Studies. Moscow: Institute of Economic Studies. In Russian (Кондратьев Н. Д. Большие циклы конъюнктуры: Доклады и их обсуждения в Ин-те экономики. М.: Рос. ассоц. н.-и. ин-тов обществ. наук, Ин-т экономики).
Kondratieff, N. D. 1928/2002. Dynamics of Industrial and Agricultural Prices. In Kondratieff 2002: 401–502. In Russian (Кондратьев Н. Д. Динамика цен сельскохозяйственных и промышленных товаров. В: Кондратьев 2002: 401–502).
Kondratieff, N. D. 1935. The Long Waves in Economic Life. The Review of Economic Statistics 17(6): 105–115.
Kondratieff, N. D. 1984. The Long Wave Cycle. New York: Richardson & Snyder.
Kondratieff, N. D. 1988[1923]. Some Controversial Questions Concerning the World Economy and Crisis (Answer to Our Critiques). Mirovaya ekonomika i mezhdunarodnye otnosheniya [World Economy and International Relations] 9: 64–76. In Russian (Кондратьев Н. Д. Спорные вопросы мирового хозяйства и кризиса (Ответ нашим критикам). Мировая экономика и международные отношения 9: 64–76).
Kondratieff, N. D. 2002. Long Cycles of Business Activity and the Theory of Foresight. Selected Works. Moscow: Ekonomika. In Russian (Кондратьев Н. Д. Большие циклы конъюнктуры и теория предвидения. Избранные труды. М.: Экономика).
Korotayev, A. V., and Grinin, L. E. 2012. Kondratieff Waves in the World System Perspective. In Grinin, L. E., Devezas, T. C., and Korotayev, A. V. (eds.), Kondratieff Waves. Dimensions and Prospects at the Dawn of the 21st Century (pp. 23–64). Volgograd: Uchitel.
Korotayev, A. V., and Grinin, L. E. 2014. Kondratieff Waves in the Global Studies Perspective. In Grinin, L. E., Ilyin, I. V., and Korotayev, A. V. (eds.), Globalistics and Globalization Studies: Aspects & Dimensions of Global Views (pp. 65–98). Volgograd: ‘Uchitel’ Publishing House.
Korotayev, A. V., Khaltourina, D. A., and Bojevolnov, Yu. V. 2010. The Laws of History. Secular Cycles and Millenial Trends. Demography, Economy, and Wars. Moscow: LKI/URSS. In Russian (Коротаев А. В., Халтурина Д. А., Божевольнов Ю. В. Законы истории. Вековые циклы и тысячелетние тренды. Демография. Экономика. Войны. М.: ЛКИ/URSS).
Korotayev, A. V., and Tsirel, S. V. 2010а. Kondratieff Waves in the World Economic Dynamics. In Khaltourina, D. A., and Korotayev, A. V. (eds.), The System-Based Monitoring of Global and Regional Development (pp. 189–229). Moscow: LIBROKOM/URSS. In Rissian (Коротаев А. В., Цирель С. В. Кондратьевские волны в мировой экономической динамике. Системный мониторинг глобального и регионального развития / Ред. Д. А. Халтурина, А. В. Коротаев, с. 189–229. М.: Либроком/URSS).
Korotayev, A. V., and Tsirel, S. V. 2010b. Kondtratieff Waves in the World-System Economic Dynamics. In Akaev, A. A., Korotayev, A. V., and Malinetsky G. G. (eds.), Forecast and Modeling of Crises and World Dynamics (pp. 5–69). Moscow: LKI. In Russian (Коротаев А. В., Цирель С. В. Кондратьевские волны в мир-системной экономической динамике. Прогноз и моделирование кризисов и мировой динамики / Ред. А. А. Акаев, А. В. Коротаев, Г. Г. Малинецкий, с. 5–69. М.: ЛКИ).
Korotayev, A., and Tsirel, S. 2010c. A Spectral Analysis of World GDP Dynamics: Kondratieff Waves, Kuznets Swings, Juglar and Kitchin Cycles in Global Economic Development, and the 2008–2009 Economic Crisis. Structure and Dynamics 4(1): 3–57. URL: http://www. escholarship.org/uc/item/9jv108xp.
Krugman, P. 2013. When Economic Wariness Becomes Folly. Nezvisimaya Gazeta, May 27 URL: http://www.ng.ru/krugman/2013-05-27/5_wariness.html. In Russian (Кругман П. Когда экономическая осмотрительность становится безрассудством. Независимая газета? Май 25).
Lenoir, M. 1913. Etudes sur la formation et le mouvement des prix. Paris: Giard.
Lescure, J. 1912. Les hausses et baisses générales des prix. Révue d’économie politique 26(4): 452–490.
Lescure, J. 1932[1907]. Des crises génerales et périodiques de surproduction. 4th ed. Paris: Domat-Montchrestien.
Linstone, H. A. 2006. The Information and Molecular Ages: Will K-Waves Persist? In Devezas, T. C. (ed.), Kondratieff Waves, Warfare and World Security (pp. 260–269). Amsterdam: IOS Press.
Lynch, Z. 2004. Neurotechnology and Society 2010–2060. Annals of the New York Academy of Sciences 1031: 229–233.
Maddison, А. 2010. World Population, GDP and Per Capita GDP, A.D. 1–2008. URL: www.ggdc.net/maddison.
Mandel, E. 1980. Long Waves of Capitalist Development. Cambridge: Cambridge University Press.
Mikhailov, D. M. 2000. The World Financial Market. Trends and Mechanisms. Moscow: Ekzamen. In Russian (Михайлов Д. М. Мировой финансовый рынок. Тенденции и инструменты. М.: Экзамен).
Mukoseyev, V. 1914. The Increase of Commodity Prices. Sankt-Peterburgh: Ministerstvo Finansov. In Russian (Мукосеев В. Повышение товарных цен. СПб.: Мин-во финансов).
Modelski, G., Thompson, W. R. 1996. Leading Sectors and World Politics: The Coevo-lution of Global Politics and Economics. Columbia, SC: University of South Carolina Press.
Nikolskiy, A. 2013. Krugman: ‘Only Bubbles and Extraterrestrial Invasion can Save Us’. URL: http://www.finmarket.ru/main/article/3552122. In Russian (Никольский А. Кругман: «Нас спасут пузыри и вторжение инопланетян». [Электронный ресурс]).
Pantin, V. I., and Lapkin, V. V. 2006. Philosophy of Historical Forecasting: Rhythms of History and Prospects of Global Development in the First Half of the Twenty-First Century. Dubna: Feniks. In Russian (Пантин В. И., Лапкин В. В. Философия исторического прогнозирования: ритмы истории и перспективы мирового развития в первой половине XXI века. Дубна: Феникс+).
Powell, B. 2003. The Explanation for the Japanese Recession. In Kuryaev, A. V. (ed.), The Master of Boom. Lessons from Japan (pp. 108–136). Cheliabinsk: Sotsium. In Russian (Пауэлл Б. Объяснение японской рецессии. Маэстро бума. Уроки Японии / под ред. А. В. Куряева, Челябинск: Социум, 2003. С. 108–136).
Parvus, A. 1901. Die Handelskrisis und die Gewerkschaften. München.
Parvus, A. 1908. Die kapitalistische Produktion und das Proletariat. Berlin: Buchhandlung Vorwärts.
Rothbard, M. 1977. Power and Market: Government and the Economy. Kansas City: Sheed Andrews and McMeel.
Rothbard, M. 1994. The Case against the Fed. Auburn, AL: Mises Institute.
Rothbard, M. 1995. Wall Street: Banks and American Foreign Policy. Auburn, AL: Mises Institute.
Rothbard, M. 2002. A History of Money and Banking in the United States: The Colonial Era to World War II. Auburn, AL: Ludwig Von Mises Institute
Rothbard, M. 2005. What Has Government Done to Our Money? Auburn, AL: Mises Institute.
Rubtsov, B. B. 2000. The World Stock Markets: Current State and Patterns of Development. Moscow: Finansovaya Akademiya. In Russian (Рубцов Б. Б. Мировые фондовые рынки: современное состояние и закономерности развития. М.: Финансовая академия).
Rubtsov, B. B. 2011. The Global Stock Markets: Scale, Structure, and Regulation. Vek Globalizatsii 2: 73–74. In Russian (Рубцов Б. Б. Глобальные финансовые рынки: масштабы, структура, регулирование. Век глобализации 2: 73–74).
Sauerbeck, A. 1886. Prices of Commodities and the Precious Metals. Journal of the Statistical Society of London 49(3): 581–648.
Scheglov, S. I. 2009. The Kondratieff Cycles in the Twenty-First Century, or How the Economic Forecasts Come True. URL: http://schegloff.livejournal.com/242360.html#cutid1. In Russian (Щеглов С. И. Циклы Кондратьева в 20 веке, или Как сбываются экономические прогнозы).
Schumpeter, J. A. 1939. Business Cycles. New York: McGraw-Hill.
Sombart, W. 1911. Die Juden und das Wirtschaftsleben. Leipzig: Duncker.
Sulakshin, S. S. 2012. The Political Dimension of Global Financial Crises. Phenomenology, Theory, and Overcoming. Moscow: Nauchniy ekspert. In Russian (Сулакшин С. С. (Ред.) Политическое измерение мировых финансовых кризисов. Феноменология, теория, устранение. М.: Научный эксперт).
Tausch, A. 2006a. From the “Washington” towards a “Vienna Consensus”? A Quantitative Analysis on Globalization, Development and Global Governance. Buenos Aires: Centro Argentino de Estudios Internacionales.
Tausch, A. 2006b. Global Terrorism and World Political Cycles. In Grinin, L., de Munck, V. C., and Korotayev, A. (eds.), History & Mathematics: Analyzing and Modeling Global Development (pp. 99–126). Moscow: KomKniga/URSS.
Thompson, W. R. 2000. The Emergence of a Global Political Economy. London: Routledge.
Thompson, W. R. 2007. The Kondratieff Wave as Global Social Process. In Modelski, G., and Denemark, R. A. (eds.), World System History, Encyclopedia of Life Support Systems, UNESCO. Oxford: EOLSS Publishers. URL: http://www.eolss.net.
Tooke, T., and Newmarch, W. 1858–1859. Die Geschichte und Bestimmung der Preise während der Jahre 1793–1857. Zwei Bände. 1–2. Dresden: R. Kuntze.
Tugan-Baranovsky, M. 1894. The Industrial Crises in Modern Britain, Their Causes and Forthcoming Impacts on People's Life. Sankt-Peterburgh: Tipografiya Skorokhodova. In Russian (Туган-Барановский М. Промышленные кризисы в современной Англии, их причины и ближайшие влияния на народную жизнь. СПб.: Тип. И. Н. Скороходова).
Tugan-Baranovsky, M. 2008 [1913]. Periodic Industrial Crises. Moscow: Direktmedia Publishing. In Russian (Туган-Барановский М. И. Периодические промышленные кризисы. М.: Директмедиа Паблишинг).
UNCTAD 2013. World Investment Report 2013: Global Value Chains: Investment and Trade for Development. New York – Geneva: UNO.
UN Population Division. World Population Prospects: The 2012 Revision. New York: United Nations, 2014.
Van Gelderen, J. 1913. Springvloed: Beschouwingen over industrieele ontwikkeling en prijsbeweging. De nieuwe tijd 18.
Vestifinance. 2013. Low Inflation Interferes the Rich Countries. URL: http://www.vestifinance. ru/articles/36414. In Russian (Богатым странам мешает низкая инфляция).
Vimont, C. 2000. Evolution demographique, marche du travail et croissance de la productivite. Problemes economiques 2656(2657): 37–41.
Wallerstein, I. 1984. Economic Cycles and Socialist Policies. Futures 16(6): 579–585.
Wicksell, K. 1898. Geldzins und Güterpreise: Eine Studie über die den Tauschwert des Geldes bestimmenden Ursachen. Jena: Fischer.
Whitney, M. 2013. Blowing Bubbles with Paul Krugman. CounterPunch, November 22–24. URL: http://www.counterpunch.org/2013/11/22/blowing-bubbles-with-paul-krugman/
World Bank. 2014. World Development Indicators Online. Washington, DC: World Bank. URL: http://data.worldbank.org/indicator.
Размещено в разделах




